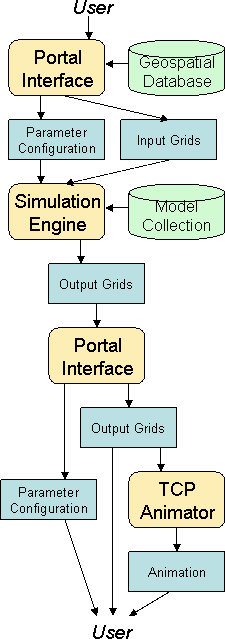
How the Tsunami Computational Portal Works
The Tsunami Computational Portal (TCP) employs a structured, wizard-style
interface to guide users through the process of setting up,
executing, and retrieving the results of model runs. Behind that
interface is a complex collection of resources, scripts, and
programs developed specifically to minimize user effort.
|
A. What the User Sees
- An account and password are required to log in to the TCP,
ensuring that use is restricted to the research community.
- The user selects a model to execute. (Two are currently
supported, and a third is now being integrated.)
- The interface steps users through the process of identifying
a geographic region for the simulation, including nested areas
to be computed at higher resolution. Selections are made
by boxing out areas on maps, specifying geographic coordinates,
or progressively narrowing an area of interest.
- Corresponding bathy/topo data are drawn from TCP's geospatial
database; metadata describing the source and nature of the
measurements are provided as well.
- The interface guides the user in setting
model parameters. Balloon help provides information on each
parameter's meaning. Default values are filled in automatically
to simplify the process for new users.
- The user submits the job for execution.
- When execution completes, the user is notified by email that
results are ready for viewing.
- After logging in, the user can now view and download the output
(a time series of grids).
- The TCP Animator visualization tool can be used to explore the
results, capture images at different stages in tsunami propagation,
or create a movie animating the time series.
- For convenience, users can examine the parameter settings that
generated those results. They may also be used as a starting point
for a new simulation, streamlining the process of conducting a series
of related simulations.
|
B. How It Really Works
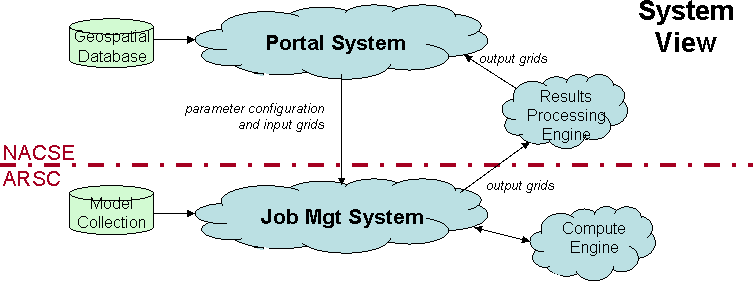
Behind the scenes, the TCP architecture is managed collaterally by
systems running at NACSE and ARSC. The Portal System (at NACSE)
is responsible
for managing interactions with users, handling interactions with
the geospatial database, packaging inputs for ARSC, and
retrieving/unpacking the results for access by users. The Job
Management System (at ARSC) handles
queuing of the job for execution, activation of the appropriate
model, and packaging of the output grids for transfer back to
NACSE.
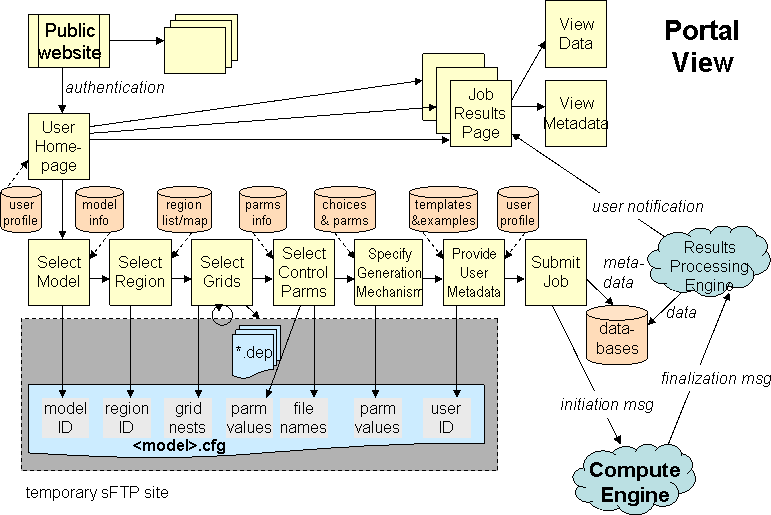
The Portal handles authentication first, then dynamically creates
a webpage displaying information on any jobs submitted on
behalf of this user, whether they are still pending or have been
completed. If the user chooses to begin a new job or pre-initialize
a new job with the settings from a previous job, the Portal guides
the user through the seven steps for creating a job (select model,
select region, select grids, select control parameters, specify
tsunami generation mechanism, provide user metadata, and submit
job). Each screen is created dynamically, using information from
the geospatial database and from files/tables maintaining information
on both general and model-specific choices. At each step, the
users choices allow the Portal to successively accrue more and
more information into a new configuration file prepared for this
job.
Once the user has completed his/her selections and submitted the
job, the Portal closes the configuration file and initiates back-end
communications (described below). When results are returned, a
subcomponent of the Portal unpacks them and stores them as part
of the archived job results.
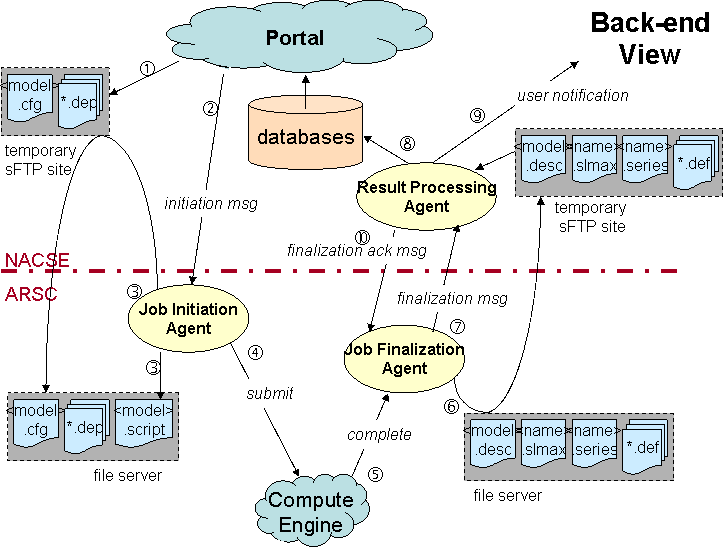
The "back-end" refers to everything that happens beyond the Portal
Interface, most of which is controlled by the Job Management system.
A number of components manage communications between NACSE and ARSC
and ensure that the job flows smoothly through the system.
The steps are outlined in the diagram below. After the configuration
file is constructed (#1), an initiation message is sent to the ARSC
job initiation agent (2). It copies the file from NACSE's secure site (3),
unpacks it, parses out the pertinent information, selects the
appropriate model executable, and prepares the job for submission (4).
Completion of the job triggers the job finalization agent (5), which
retrieves the files that were generated, packages them up, and
transfers them to NACSE's secure FTP site (6). A finalization message
is sent to alert the NACSE result processing agent (7). That agent
unpacks and transfers the files (8), then notifies the user by email
that the job has completed (9). The agent also sends an acknowledgement
to the ARSC agent that the files have been safely received (10), so
that they can now be purged on the ARSC file server.
C. Additional Information
Inventory of TCP system components and files
Common Characteristics of Tsunami Models
Definition of TCP Common Input and Output Formats
Browseable TCP Database Schema (opens in new window)
UAF Model technical description
COMCOT Model - technical description